大型语言和多模态模型的训练计算量也在稳步增加(图1.2.16)。用于训练Minerva(540B)的计算量大约是OpenAI的GPT-3(2022年6月发布)的9倍,是GPT-2(2019年2月发布)的1839倍。Minerva是谷歌于2022年6月发布的一个大型语言和多模模型,在定量推理问题上表现出了令人印象深刻的能力。
2019-22年选择大型语言和多模态模型的训练计算(FLOP)
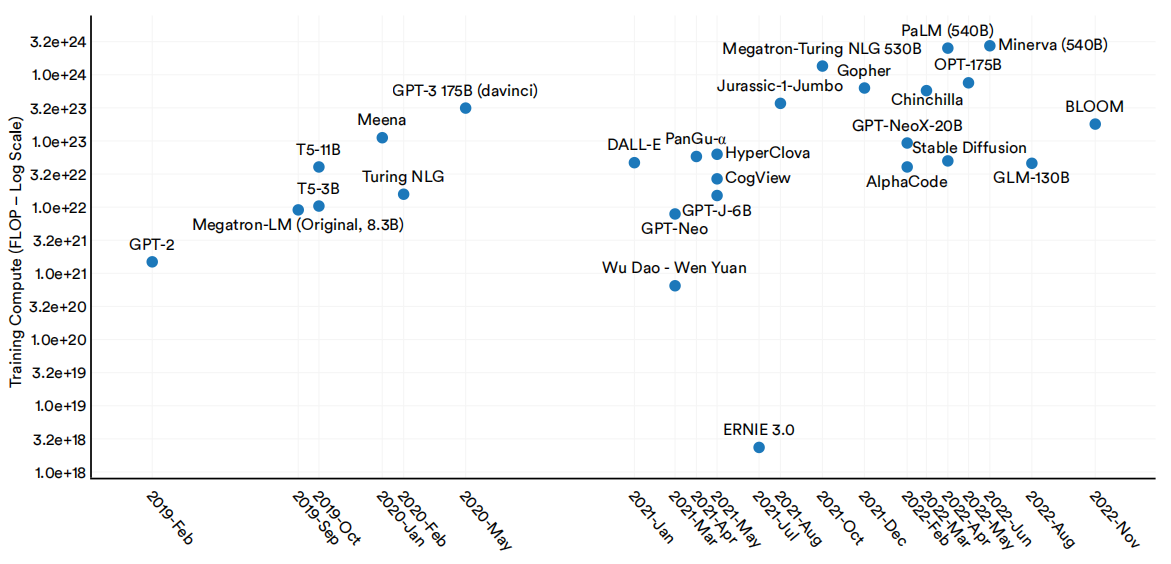
图1.2.16
训练费用
围绕大型语言和多模态模型的话语的一个特殊主题与它们的假设成本有关。尽管人工智能公司很少公开谈论训练成本,但人们普遍猜测,这些模型的训练成本为数百万美元,而且随着规模的扩大,成本将变得越来越昂贵。本小节介绍了一种新的分析,其中人工智能索引研究团队对各种大型语言和多模态模型的训练成本进行了估计(图1.2.17)。这些估计是基于模型的作者所披露的硬件和训练时间。在没有透露训练时间的情况下,我们根据硬件速度、训练计算和硬件利用率效率进行计算。考虑到估计值的可能可变性,我们用中、高或低的标签来限定每个估计值:中估计值被认为是中级估计值,高被认为是高估估计值,低被认为是低估估计值。在某些情况下,没有足够的数据来估计特定的大型语言和多模态模型的训练成本,因此这些模型在我们的分析中被省略了。
选择大型语言和多模态模型的估计训练成本
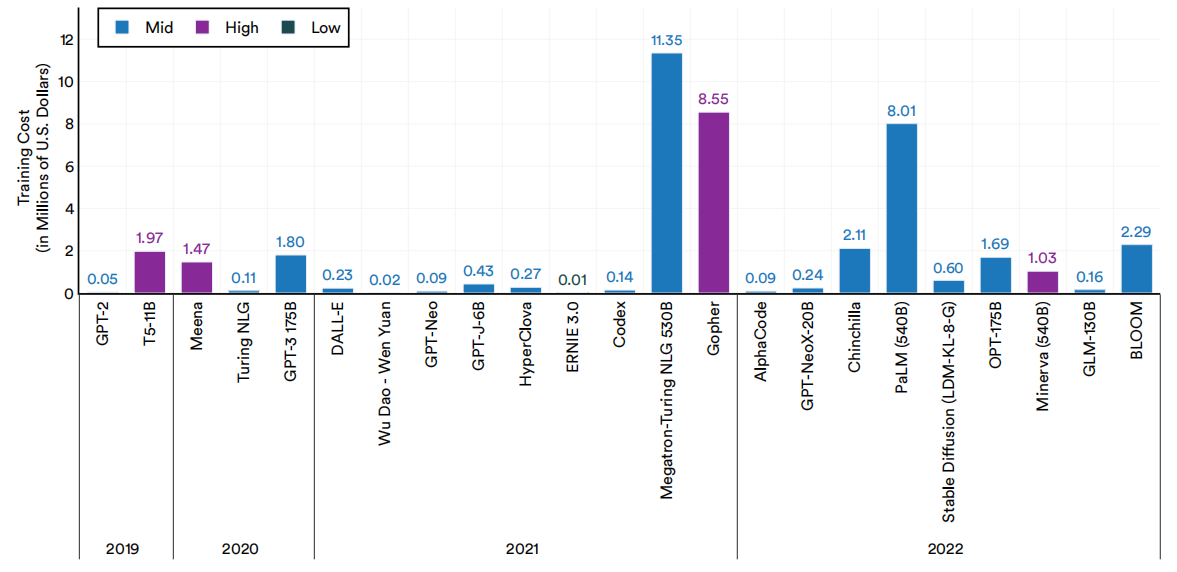
图1.2.17
大型语言和多模态模型的成本与其规模之间也有明显的关系。如图1.2.18和1.2.19所示,具有更多参数的大型语言和多模态模型以及使用大量计算的训练往往更昂贵。
选择大型语言和多模态模型的估计训练成本和参数数
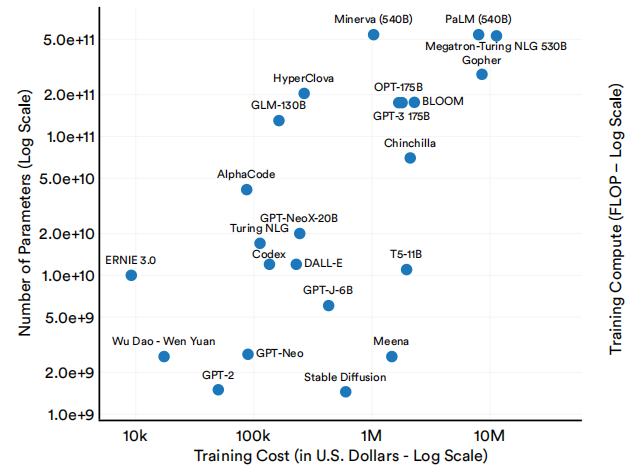
图1.2.18
选择大型语言和多模态模型的估计训练成本及训练计算(FLOP)
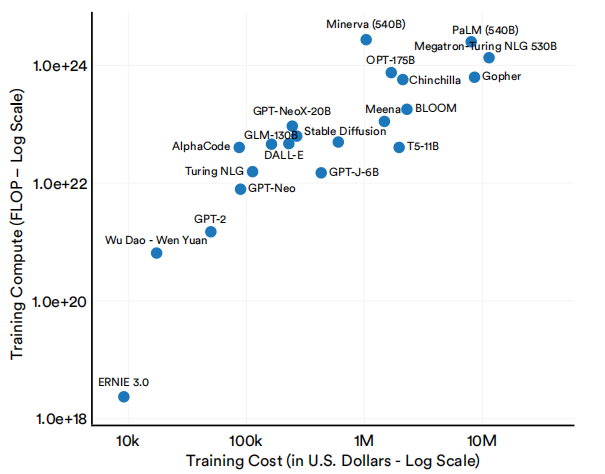
图1.2.19
人工智能会议是研究人员分享其工作、与同行和合作者建立联系的关键场所。出席会议表明了人们对一个科学领域的更广泛的工业和学术兴趣。在过去的20年里,人工智能会议的规模、数量和声望都有所增长。本节介绍了参加主要人工智能会议的趋势数据。












 粤公网安备 44010602004351号
粤公网安备 44010602004351号