参数是由机器学习模型在训练过程中学习到的数值。机器学习模型中的参数值决定了模型如何解释输入数据并做出预测。调整参数是确保机器学习系统的性能得到优化的一个必要步骤。图1.2.9按部门突出显示了Epoch数据集中包含的机器学习系统的参数数量。随着时间的推移,参数的数量一直在稳步增加,自2010年代初以来,这个增长尤为急剧。人工智能系统正在迅速增加其参数的事实反映了它们被要求执行的任务的复杂性增加,数据的可用性增加,底层硬件的进步,最重要的是,更大的模型的性能演示。
1950-22年按部门划分的重要机器学习系统的参数数量
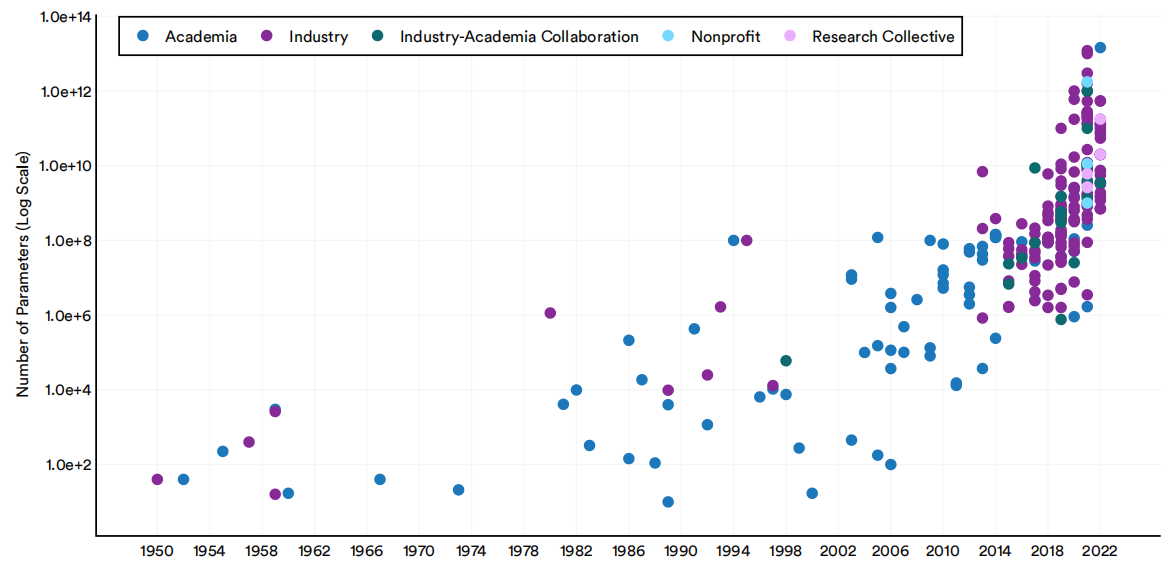
图1.2.9
图1.2.10按领域展示了机器学习系统的参数。近年来,参数丰富的系统数量不断增加。
1950-22年重要的机器学习系统按领域划分的参数数
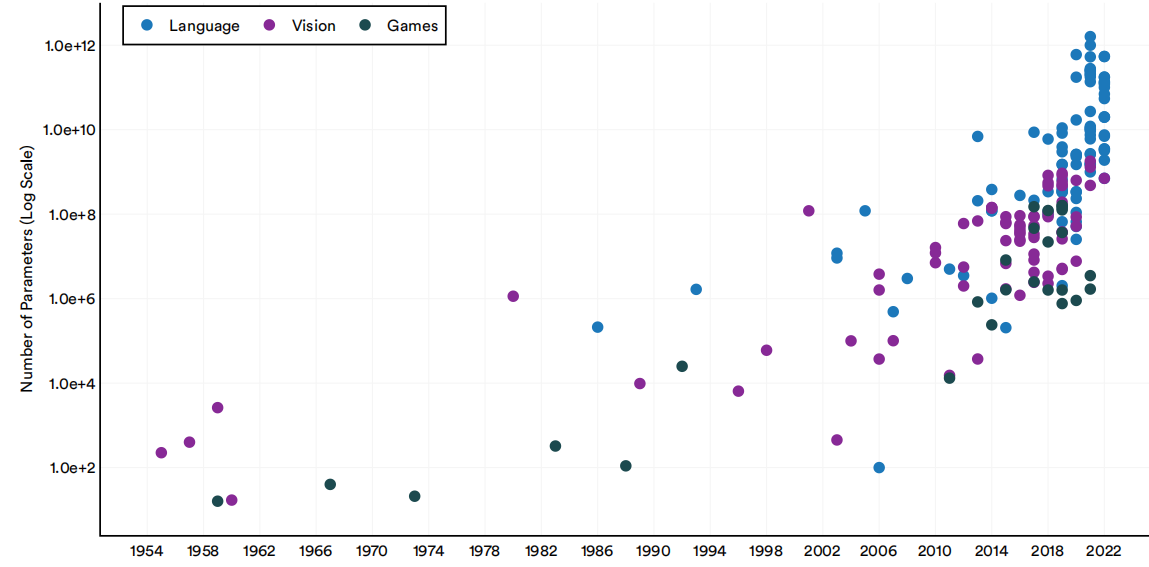
图1.2.10
计算趋势
人工智能系统的计算能力,或称“计算能力”,是指训练和运行机器学习系统所需的计算资源量。通常,一个系统越复杂,所训练它的数据集越大,所需的计算量就越大。在过去的五年里,重要的人工智能机器学习系统使用的计算量呈指数级增长(图1.2.11)。对人工智能计算需求的增长有几个重要的影响。例如,更密集型计算的模型往往对环境的影响更大,而工业参与者往往比大学等其他模型更容易获得计算资源。
1950-22年重要机器学习系统的分部门训练计算(FLOP)
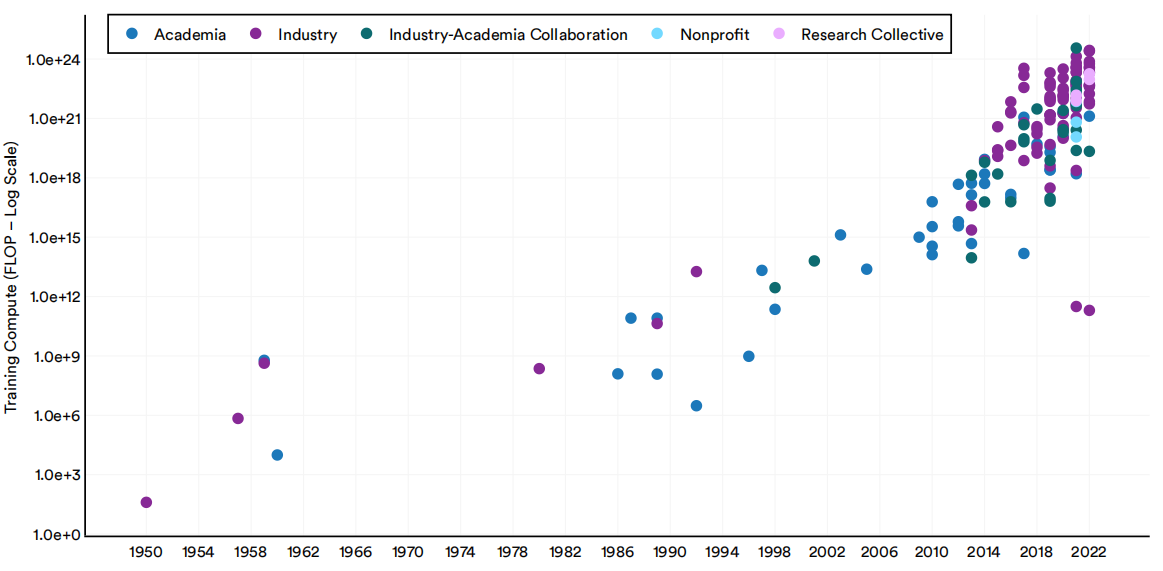
图1.2.11
自2010年以来,在所有的机器学习系统中,语言模型需要的计算资源越来越多。
1950-22年重要机器学习系统的分域训练计算(FLOP)
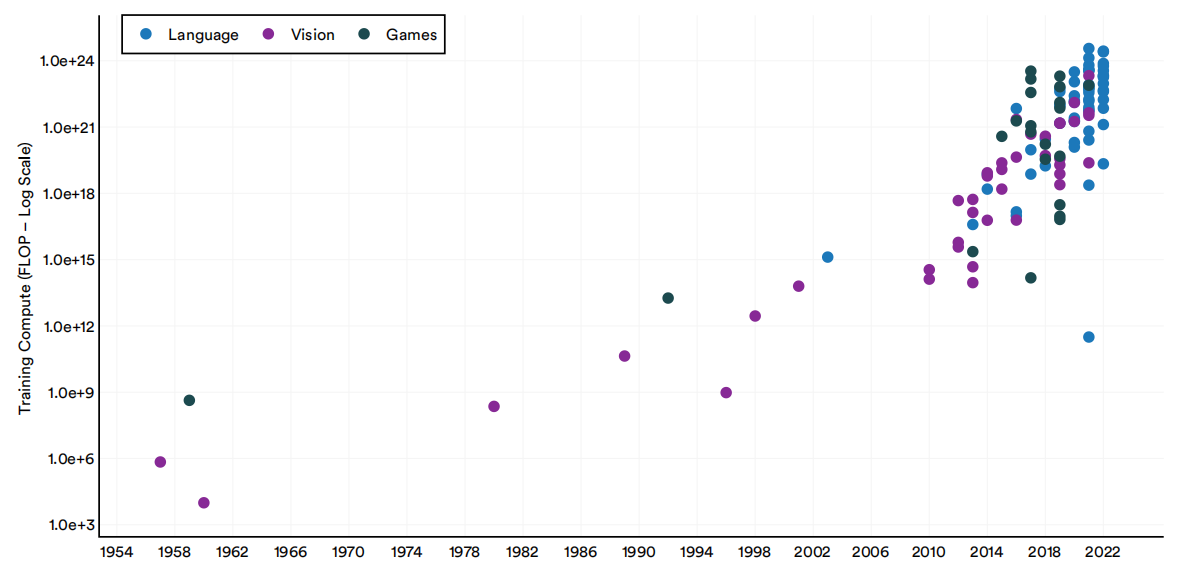
图1.2.12
大型语言和多模态模型
大型语言和多模态模型,有时被称为基础模型,是一种新兴的、日益流行的人工智能模型,它对大量数据进行训练,并适应各种下游应用程序。像ChatGPT、DALL-E 2和MakeA-Video这样的大型语言和多模态模型-Video模型已经展示了令人印象深刻的能力,并开始在现实世界中广泛应用。今年,人工智能指数对负责发布新的大型语言和多模态模型的作者的国家隶属关系进行了分析。10这些研究人员中的大多数来自美国的研究机构(54.2%)(图1.2.13)。2022年,来自加拿大、德国和印度的研究人员首次为大型语言和多模式模型的发展做出了贡献。
2019-22年按国家选择大型语言和多模态模型(占总数的%)的作者
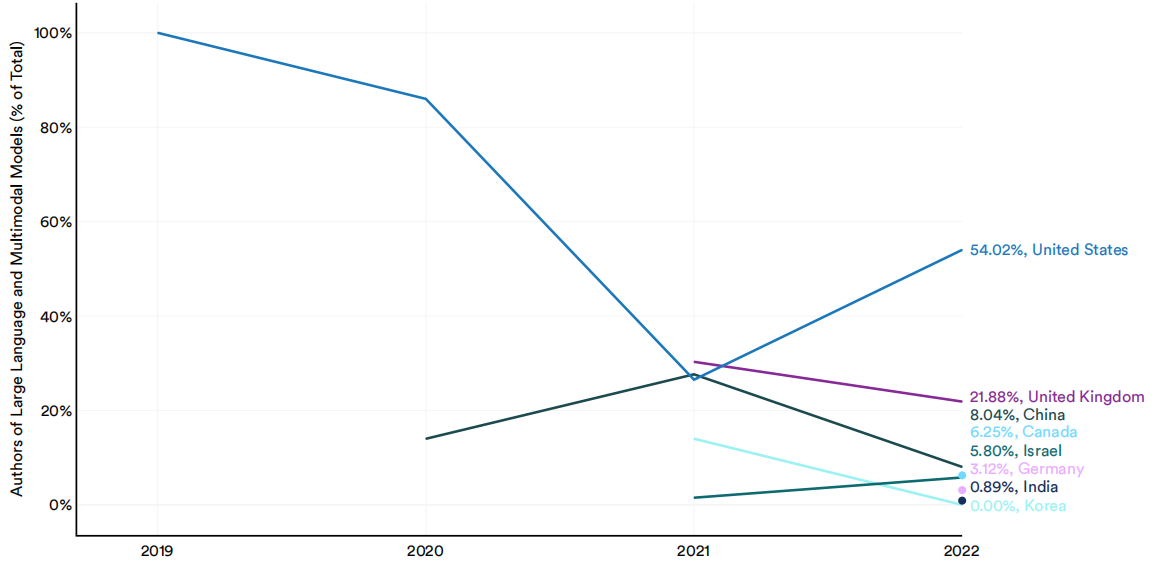
图1.2.13
图1.2.14提供了自GPT-2以来发布的大型语言和多模态模型的时间轴视图,以及产生这些模型的研究人员的国家附属机构。2022年发布的一些著名的美国大型语言和多模态模型包括OpenAI的DALL-E 2和谷歌的PaLM(540B)。2022年发布的唯一一种中国大型语言和多模式模式是GLM-130B,这是清华大学的研究人员创建的一种令人印象深刻的双语(英语和中文)模式。同样于2022年底推出的布鲁姆计划,由于它是1000多名国际研究人员合作的结果,因此被列为不确定计划。
选择大型语言和多语言模式模型发布的时间轴和国家归属
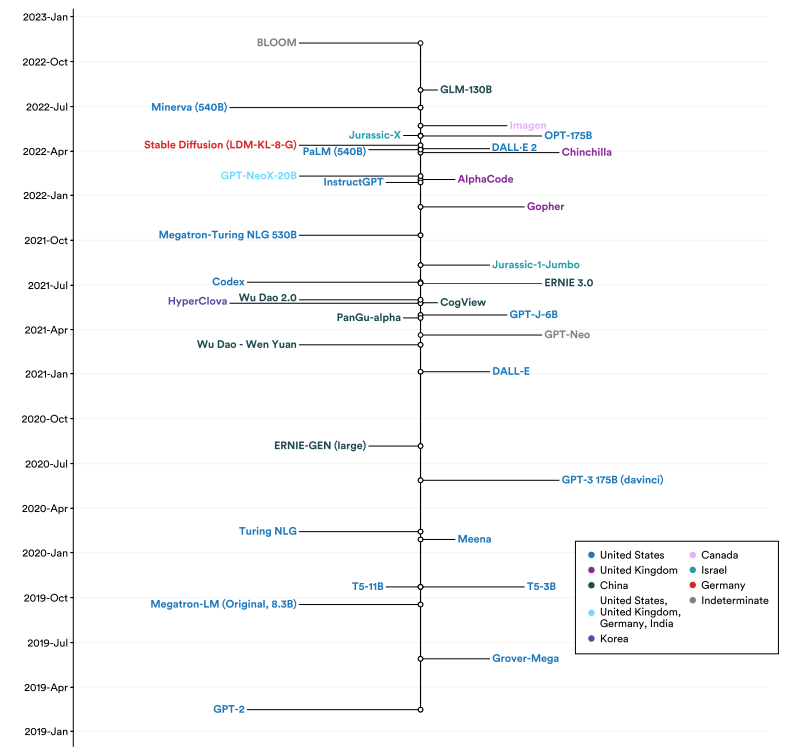
图1.2.14
参数计数
随着时间的推移,新发布的大型语言和多模态模型的参数数量大幅增加。例如,GPT-2是2019年发布的第一个大型语言和多模式模型,它只有15亿个参数。由谷歌于2022年推出的PaLM拥有5400亿美元,是GPT-2的近360倍。在大型语言和多模态模型中,参数的中位数随着时间的推移呈指数级增长(图1.2.15)。
2019-22年选择大型语言和多模态模型的参数数
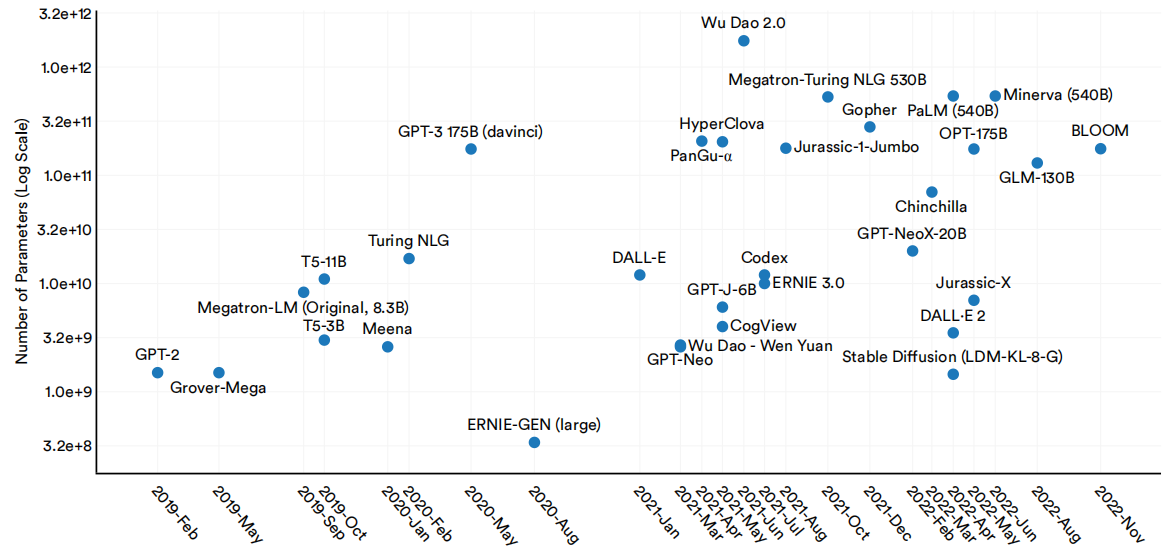
图1.2.15












 粤公网安备 44010602004351号
粤公网安备 44010602004351号