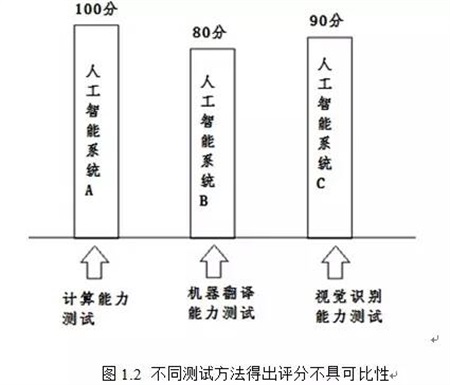
每种具体的人工智能系统往往只具备一个或若干上述提到的功能。例如IBM的深蓝强于计算能力,在国际象棋方面可以与人类对手一决高下;沃森系统拥有庞大知识库系统,因此可以在常识问答比赛中击败人类选手。因为没有统一的模型可以涵盖这些人工智能系统,就无法形成统一的测试方法进行测试和比较。如图1.2所示,人工智能系统A 在计算能力上得分为100,人工智能系统B 在计算机视觉识别上得分为80,人工智能系统C在机器翻译测试得分为90分,我们仍然无法得出结论A的智力能力高于C,C的智力能力高于B的结论。
(2)第二个困难是没有统一的模型和测试方法,能够同时对人工智能系统和人类进行测试,这也是当前人工智能威胁论产生最重要的原因之一。因为没有人工智能系统和人类智能水平统一的测量方法,人工智能威胁论宣扬者往往将计算机或软件系统表现强大的领域作为标准,例如计算能力,历史,地理等常识的掌握能力等,而忽略诸如图像识别能力,创新创造的能力,发现规律的能力等,对于这个原因产生的问题,人工智能威胁论反驳者往往无法拿出定量的数字结果进行反驳。
目前虽然针对人类智力能力的评测方法已经非常成熟,但过去100多年的发展和改进过程中,这些方法并没有考虑到人工智能系统的特点和发展水平,因此很难将人类的智商测试方法拿来测试人工智能系统。例如目前绝大多数人工智能系统就无法完成图1.3所示题目,因为测试者需要首先识别图像中的问题,并与图中的各个图形特征关联起来。做不到这一点,回答问题就无法进行下去。
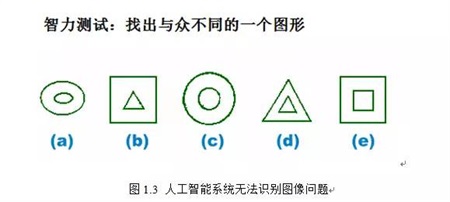
图1.4所示的人类智商测试的题目需要测试者运用铅笔,钢笔等工具绘制图形。用手操作物体完成任务,解决问题是人类普通的能力,但对大多数人工智能系统因为没有相应输出系统或操控设备,于是无法完成图1.4所示的测试。












 粤公网安备 44010602004351号
粤公网安备 44010602004351号